Step Aside Resolvers - Grafast 0.1 Released!

Grafast is finally here — a new holistic execution engine for GraphQL. It enables greater efficiency across the entire backend stack by leveraging the declarative nature of GraphQL to give your business logic a better understanding of everything it needs to do. It’s backwards compatible, so you can adopt it incrementally within your existing schema and it’s finally ready to try with the grafast module on npm; or check out the source code on GitHub!
I launched Grafast v0.1 at GraphQL Conf, above is the full video of my talk which covers what Grafast is and how it can improve application performance, reduce operational costs, all without being a significant burden on developers.
Grafast Working Group
There’s still decisions to be made and edges to be smoothed before Grafast can become a specification that can be implemented in any language. If the potential of this technology is interesting to you, please join the Grafast working group and get involved. We all deserve our future of easy GraphQL execution efficiency!
If you don’t have time to watch the video above, here’s a little about Grafast:
“GraphQL’s execution model is wrong for most servers”
GraphQL is a declarative language; the requests specify everything that the client is asking for up–front.
But the resolver–based execution model obfuscates this knowledge — when implemented naively, resolvers can very quickly result in serious performance issues; and even when implemented well they leave a lot to be desired.
DataLoader is one of the suggested approaches to solve the “N+1 Problem” but this is only the most egregious performance issue a GraphQL schema may face — there are plenty of related issues that can build up as your schemas and operations get more complex.
I set out not only to solve the well–known N+1 problem and the more subtle under– and over–fetching problems, but to help you achieve the most efficient execution for your GraphQL schema no matter what data sources you’re working with! The solution? Leverage the declarative nature of GraphQL via a new general purpose query planner.
“Step aside resolvers! There’s a new way to execute GraphQL”
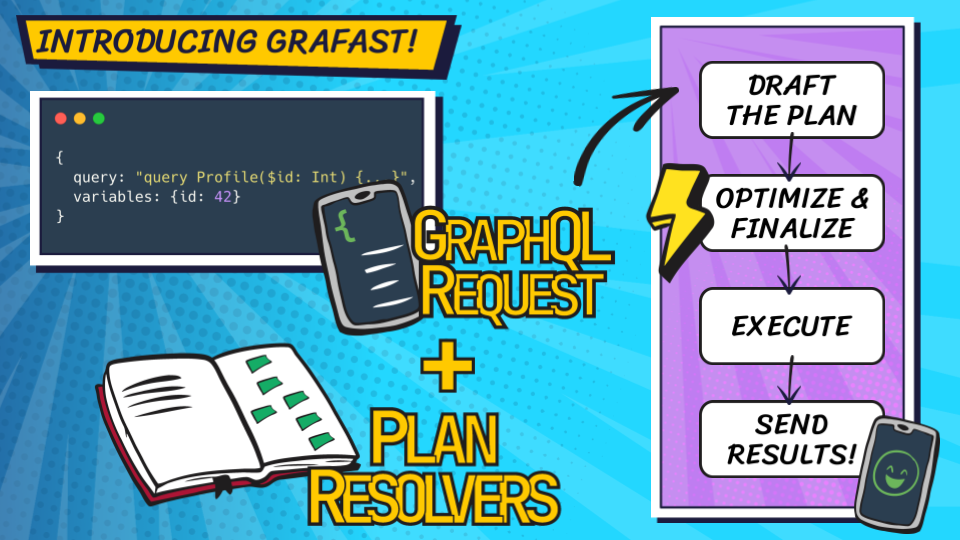
Grafast calls “plan resolvers” to determine the requirements for each field in the GraphQL request, ultimately forming a draft “operation plan”. Once drafted, the plan is optimized and executed.
Grafast has been designed from the ground up to give schema designers the tools they need to ensure their schemas are executing as efficiently as possible, whilst ensuring that writing their logic is still a pleasant experience. To achieve this, Grafast favours a planning strategy which takes a holistic approach to understanding the incoming operation and unlocks the potential for significant optimizations: optimizations that are not achievable with a resolver–based execution model unless one puts in herculean effort (and a little sorcery 😉).
Grafast, like GraphQL, is not specific to any particular technology stack, business logic shape or data storage layer. It doesn’t care if you’re using relational databases, document stores, ORMs, HTTP APIs, file systems or carrier pigeons. Any valid GraphQL schema can be implemented with Grafast, and a Grafast schema can query any data source, business logic or service.
Though it supports traditional resolvers, Grafast encourages developers to use “plan resolvers”: small functions similar to resolvers but which describe the required data, rather than actually fetching it.
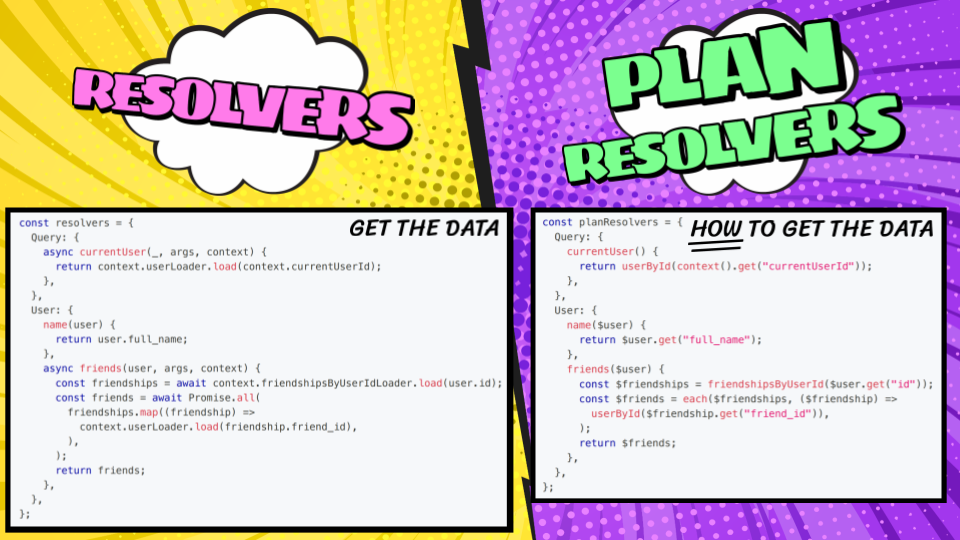
Plan resolvers are similar to traditional resolvers, they even follow the same shape, but the key difference is they describe HOW to get the data rather than actually fetch it themselves.
Grafast takes the GraphQL request and, using the plan resolvers, drafts an execution plan which can be optimized and streamlined. The optimization may involve changing the shape of execution significantly from the shape the GraphQL request would imply, enabling the system to satisfy the requirements of the request in the most efficient manner.
When the planning phase is complete, Grafast will execute this highly optimized execution plan, and feed the result into the output plan, which efficiently prepares the result to send to the GraphQL client.
If another request comes in using the same GraphQL document but different variables, Grafast can reuse the plan and jump straight to the highly optimized execution phase.
This greater understanding of the needs of the GraphQL requests unlocks entire new avenues for optimization, without sacrificing tried–and–trusted approaches such as caching. The result is greater efficiency — not just in your GraphQL server, but also in the backend services that it relies on — letting your team operate with a simpler architecture for much longer, allowing your engineers to focus on shipping better experiences for your customers rather than on the complexities of keeping a complicated architecture running smoothly.
Probably worth looking into the work @Benjie is doing with Grafast as well. Feels like the missing substrate in the GraphQL world.
— Sean Grove (@sgrove)
August 29, 2023
Grafast already works and some of my sponsors are already running it in production. You can try it out today by following the guide at grafast.org. All that’s left for me to say now is, if the potential of this new technology is interesting, then please:
Help shape the future on 24th October and join the Grafast working group!
