Grafast V1; solving GraphQL's execution woes


Grafast V1.0.0 is live!
A radical new approach to GraphQL execution: Grafast’s breadth-first, batched, plan-based execution model integrates deeply with your business logic, making previously challenging optimizations straightforward whilst eliminating the costs and failure modes of traditional resolvers.
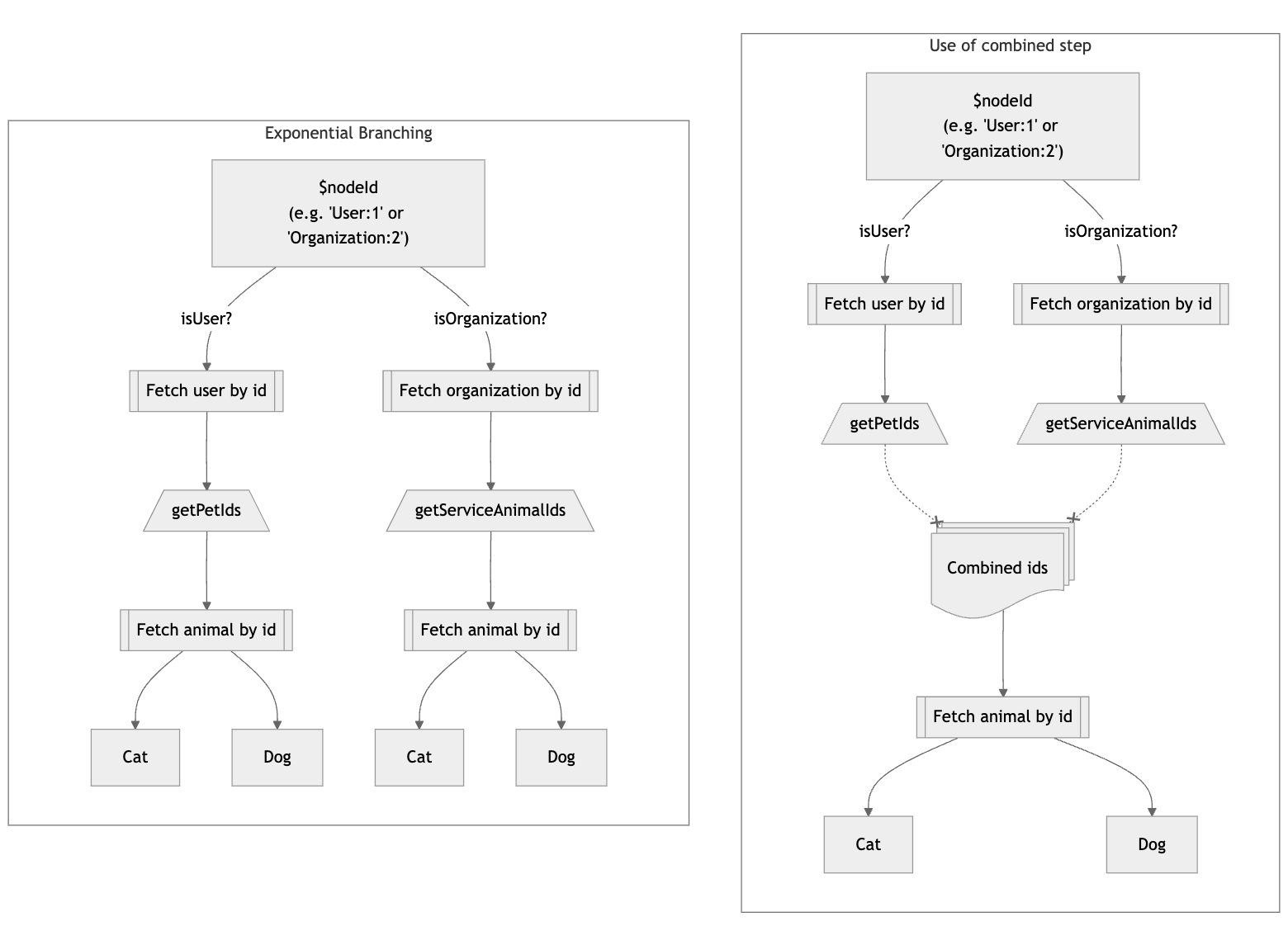
Many don’t realise just how costly traditional GraphQL execution can be until it’s too late. The GraphQL specification outlines a reference execution algorithm that focusses on being clear and instructive rather than efficient, but implementations may use any solution so long as the perceived result is equivalent. GraphQL.js — the GraphQL reference implementation — follows the reference execution algorithm nearly verbatim, passing the problems of the depth-first “resolver” pattern down to consumers.
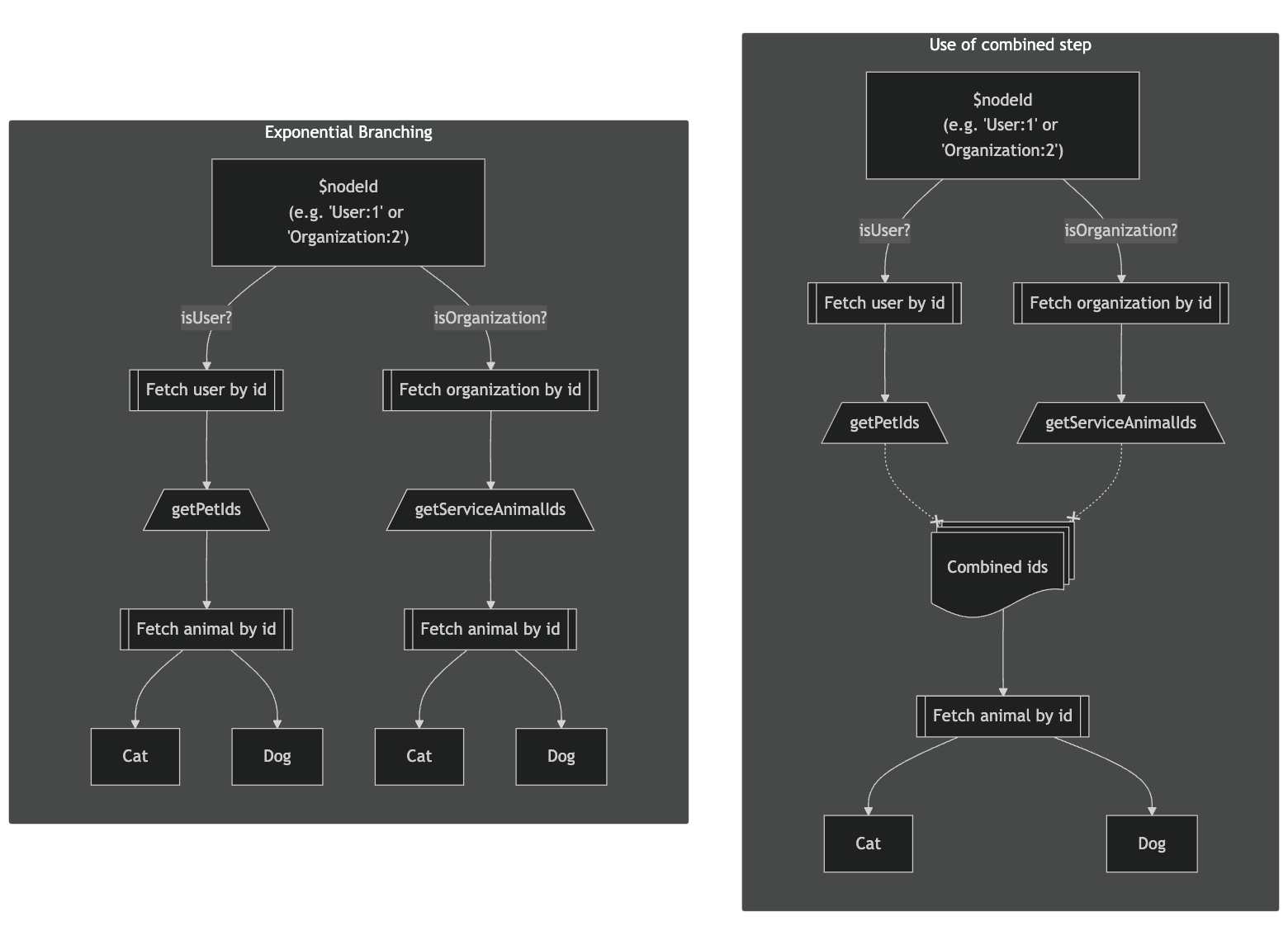
Grafast is a radical alternative execution algorithm focussing on efficiency throughout the stack. Instead of the myopic resolver model of GraphQL.js which has limited coordination with business logic, Grafast takes a holistic approach by planning the full request and optimizing business logic integration before executing it, whilst being sure to keep the perceived result equivalent for spec compliance.
When an operation is seen for the first time, planning begins: each field indicates its data needs and planned execution steps via synchronous “plan resolvers”. The resulting plan is then deduplicated and optimized so that the minimal number of steps, each backed by a batched function, are scheduled for execution. This final plan can be re-used for compatible future requests.
When executing the plan, the number of calls to these functions is independent of the size of the various lists, no matter how deeply they are nested, leading to predictable and scalable execution.
Greater efficiency throughout the stack
Grafast isn't just about making GraphQL execution itself more efficient; it aims to reduce computation costs and latency across your entire backend stack. No more backend over- and under-fetching. Eliminate the N+1 problem, reduce round-trips, and cut serialization/deserialization costs by fetching less data from your datastores.
You can also say goodbye to exponentially increasing resolver and telemetry calls in nested lists. Grafast even reduces event loop tick counts, eliminates per-request AST traversal, and produces the JSON payload directly without intermediate objects.
Backwards compatible
Grafast has a resolver compatibility layer that means that many existing GraphQL.js projects can move directly to Grafast. The requirements for existing schemas to be compatible with Grafast are outline in the using Grafast with an existing GraphQL.js project documentation. We hope to expand this compatibility to cover more esoteric resolvers over time.