

In the first Grafast Working Group, we outlined 4 major issues in Grafast that needed to be addressed before we could think about general release. The fourth, and final, epic has now been solved!
- ✅ Global dependencies — solved via “unary” steps
- ✅ Early exit — solved via “flags”
- ✅ Eradicating eval
- ✅ Polymorphism — this release!
In previous versions of Grafast there was the possibility of exponential plan
branching due to the naive method of resolution of abstract types — a known
issue raised in the first Grafast working group as one of four “epics” to be
solved before v1.0. This release of [email protected] fixes this final epic through
a complete overhaul of the polymorphism system. Let’s take a look!
Polymorphism epic achieved
By moving the responsibility of polymorphic resolution from field plan resolvers
into the abstract types themselves, we’ve centralized this logic, simplified
field plan resolvers, and unlocked more optimization opportunities and greater
execution efficiency. We no longer have the concept of “polymorphic capable”
steps: any step may now be used for polymorphism. Abstract types now gain a
planType method responsible for taking a “specifier” from the field plan
resolver and returning a step representing the name of its concrete object type
along with subplans for each possible object type.
To solve the problem of exponential branching, we merge the new specifier steps from all previous polymorphic branches into a single “combined” step before planning the next level of polymorphism.
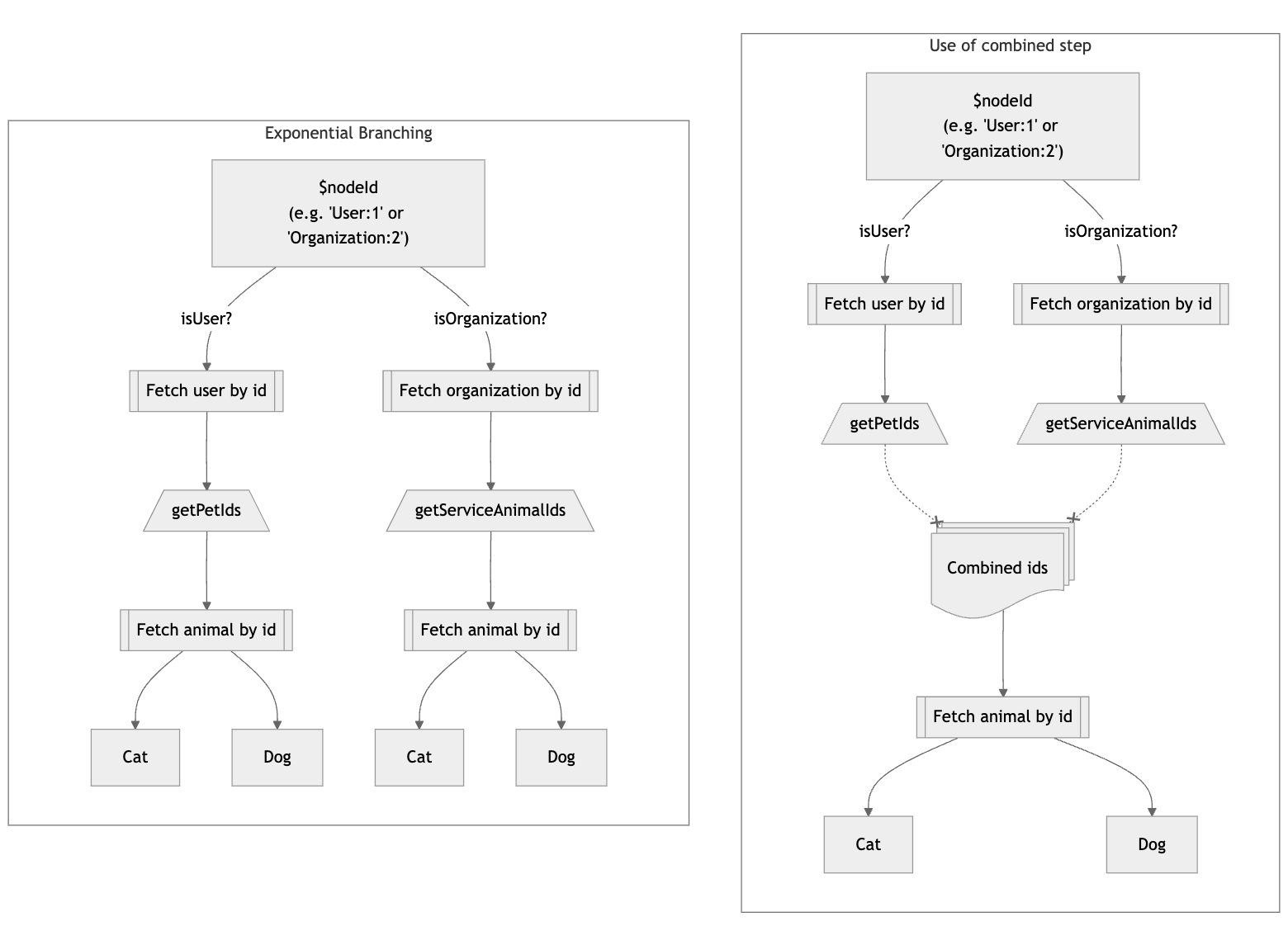
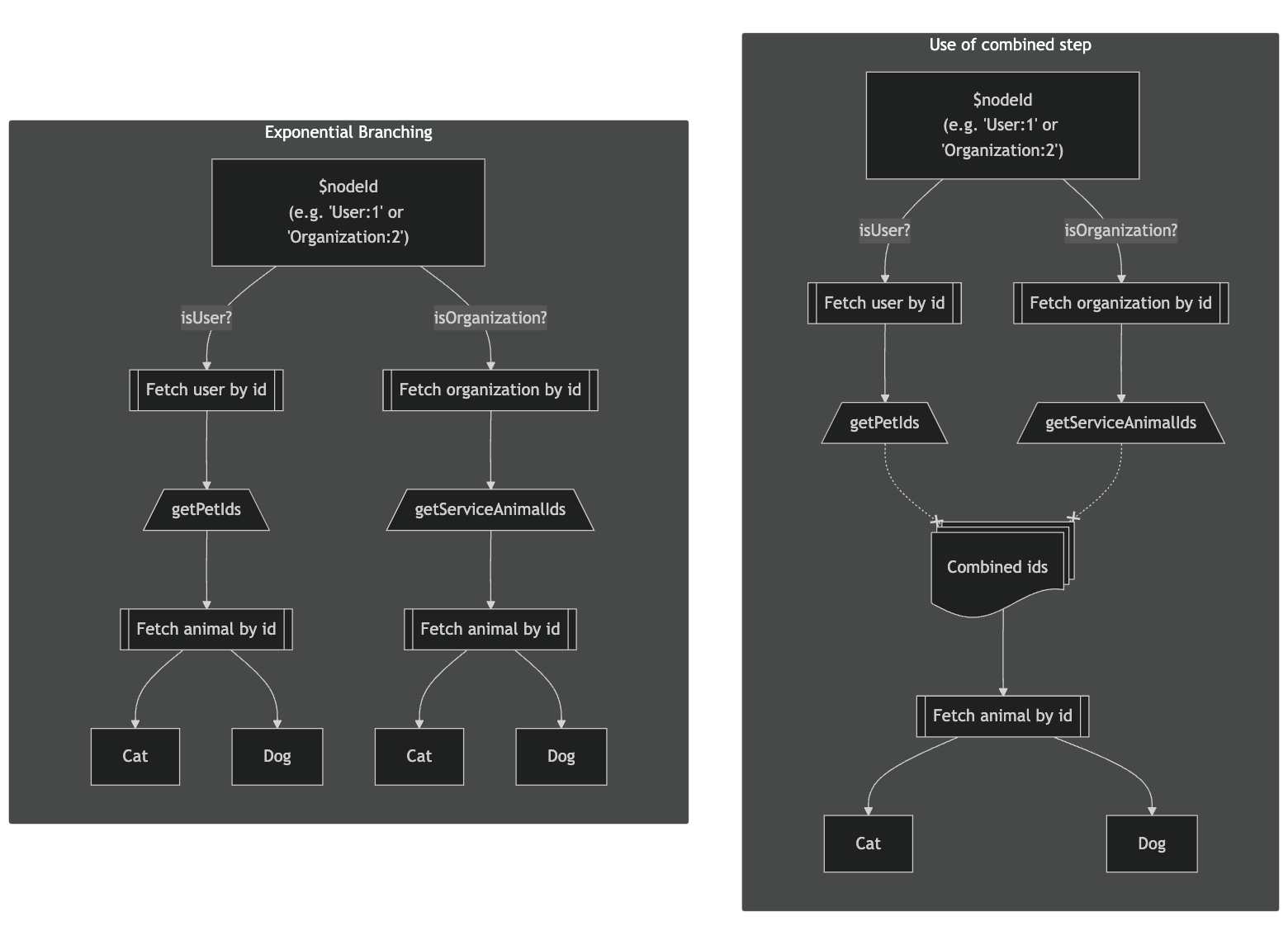
getPetIds and getServiceAnimals both fetch an Animal ID and so they are combined together in order to fetch all of the required Animals by their IDs. Once the IDs are fetched, the nodes can branch out to the different Animal types.